
Understanding Insurance Fraud and the Tech Opportunity
The Scope and Sophistication of Modern Insurance Fraud
Insurance fraud encompasses a wide range of illegal activities, from staged accidents and inflated repair estimates to fake identities and entirely fictitious claims. These schemes are often well-organized and executed by individuals or rings that understand insurance processes intimately. Their adaptability makes detection increasingly difficult for manual systems.
Why Traditional Methods Fall Short
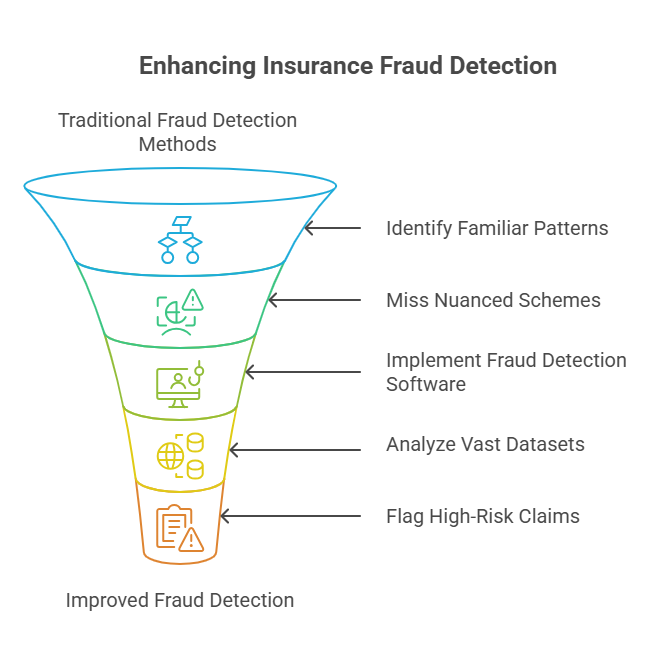
Conventional approaches to fraud detection rely heavily on predefined rules and static scorecards. These methods can catch familiar patterns but often miss nuanced or novel schemes. They are time-consuming to update and highly dependent on human expertise, making them ineffective against sophisticated fraudsters operating in real-time.
The Role of Insurance Fraud Detection Software
Insurance fraud detection software uses machine learning algorithms that analyze vast datasets to uncover anomalies. These tools adapt to new data and changing patterns, providing a far more flexible and scalable solution than human-centric processes. They flag high-risk claims for review, improving investigative accuracy while reducing false positives.
Strategic Value for Enterprises
For corporate stakeholders, implementing fraud detection technology isn’t just about loss prevention. It’s about reinforcing the company’s reputation, ensuring faster payouts to genuine claimants, and aligning with stringent compliance requirements. These solutions ultimately create a more efficient and resilient claims ecosystem, enabling insurers to outperform competitors who still rely on legacy systems.
Challenges in Detecting Insurance Fraud
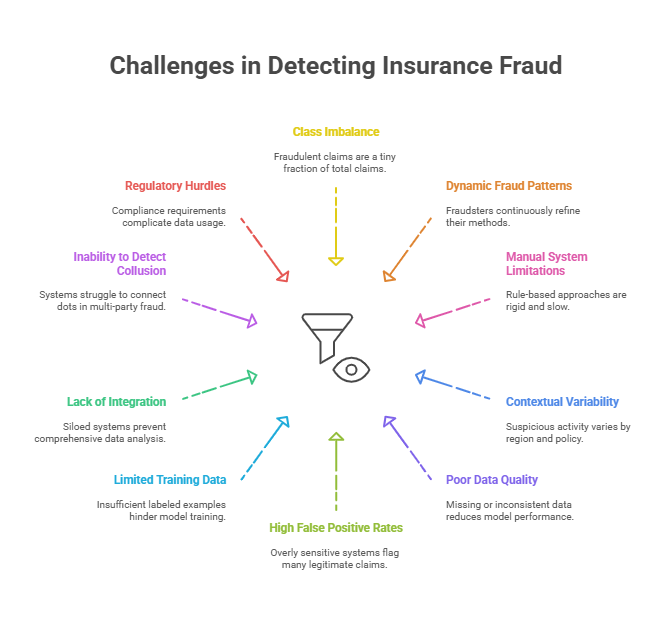
Detecting insurance fraud is among the most complex problems insurers face today. Fraud tactics evolve constantly, data is often messy, and fraud is rare, making it difficult to catch without triggering false alarms. Traditional methods are no longer sufficient. Addressing these challenges requires a detailed understanding of their nature and impact.
Class Imbalance
Fraudulent claims represent a tiny portion of total claims; typically less than 1%. This makes it difficult for models to learn meaningful patterns without bias toward the majority (non-fraud) class. As a result, standard machine learning techniques often fail unless carefully tuned for imbalanced data.
Dynamic Fraud Patterns
Fraudsters continuously refine their methods. What looked suspicious last year might now seem normal. Static models quickly become outdated, allowing new fraud techniques to slip through the cracks. This necessitates adaptive systems that learn continuously and evolve with new threats.
Manual System Limitations
Rule-based approaches need constant updates and rely heavily on expert input. These systems often become rigid, slow, and ineffective over time. Investigators can be overwhelmed by false positives, leading to wasted time and missed actual frauds.
Contextual Variability
What constitutes suspicious activity can vary based on region, policy type, or customer demographics. A one-size-fits-all model may work well in one geography and fail completely in another. Models must account for these variations to remain effective.
Poor Data Quality
Missing or inconsistent data is common in claims processing. Mistakes in data entry, duplicated records, or incomplete claim files can reduce model performance significantly. Effective fraud detection relies on data preparation and cleansing.
High False Positive Rates
Overly sensitive systems may flag many legitimate claims as fraudulent, straining investigative teams and delaying payouts. This can harm customer satisfaction and erode trust, especially when valid claims are incorrectly flagged.
Limited Training Data
There are often too few labeled examples of fraud to train effective models. Without quality examples, machine learning tools can struggle to identify subtle fraud behaviors, leading to either overfitting or underperformance.
Lack of Integration
Many insurance firms use siloed systems where data isn’t centralized. This fragmentation makes it harder to analyze complete claims histories or spot coordinated fraud across multiple policies or lines of business.
Inability to Detect Collusion
Some frauds involve multiple parties; policyholders, repair shops, or even insiders. Rule-based systems struggle to connect such dots. Advanced insurance fraud detection software must identify relational patterns and coordinated activity.
Regulatory Hurdles
Different markets have varying compliance requirements. Fraud detection systems need to operate within legal frameworks that often restrict certain types of data usage, making implementation more complex without violating privacy laws.
Without advanced insurance fraud software, these challenges often leave insurers vulnerable, slow, and reactive in the face of fast-evolving threats.
Role of Technology in Modern Fraud Detection
Machine learning and AI have emerged as transformative tools in combating insurance fraud. Modern insurance fraud detection software replaces subjective rules with data-driven insights. Instead of asking what a suspicious claim looks like, the software analyzes past frauds and uncovers hidden patterns that indicate fraud in new claims.
Scalability
Advanced fraud detection systems can process millions of claims simultaneously without compromising speed or accuracy. By automating the detection process, these systems eliminate manual backlogs and ensure that no potential fraud is missed due to volume. This scalability is vital for enterprise-level insurers managing high claim throughput across multiple regions.
Adaptability
Fraud patterns are dynamic, so detection models must evolve continuously. Machine learning-based systems adapt through ongoing training on new datasets and feedback from past investigations. This capability allows them to recognize emerging fraud tactics and remain effective in a changing threat environment without requiring constant manual recalibration.
Precision
Accurate identification of fraudulent activity minimizes disruption to genuine policyholders. Precision-focused models use refined scoring algorithms and pattern recognition to flag high-risk claims with minimal false positives. This sharpens investigator focus and ensures that time and resources are spent only where they’re most likely to uncover fraud.
Speed
Time is critical in fraud prevention. Real-time detection engines scan incoming claims instantly, allowing suspicious activity to be flagged before disbursements occur. This proactive approach protects insurers from preventable losses and builds confidence in the efficiency of the claims process among customers and regulators.
Ready to Future-Proof Your Fraud Detection Strategy?
Discover how Neuronimbus can build the right insurance fraud detection software tailored to your business.
Book a Free Consultation
Key Features of Insurance Fraud Detection Software
Executive leaders evaluating technology solutions must look for the following in their insurance fraud detection software:
Hybrid Detection Models
The best systems blend business rules with machine learning algorithms, combining the expertise of industry professionals with the scalability and learning power of AI. This dual approach ensures accuracy even in cases that deviate from historical fraud patterns, increasing detection success rates.
Anomaly Detection
Anomaly detection engines spot irregularities in both structured and unstructured data. These include strange claim timing, conflicting details, or duplicate data entries. By flagging unusual activity patterns that don’t fit normal behavior, these features help identify both known and novel fraud tactics.
Case Triaging
Fraud teams are often overwhelmed with alerts. Case triaging tools score each alert by urgency, financial impact, and likelihood of fraud. This helps investigators prioritize high-risk cases, optimize resources, and avoid burnout while still ensuring comprehensive oversight.
Integrated Dashboards
Dashboards provide real-time visibility into fraud detection activity, investigations, and model performance. With visual reporting tools, leadership teams can track trends, monitor team efficiency, and justify actions to internal stakeholders and external auditors alike.
Audit Trails
Regulatory compliance requires detailed tracking of every step taken in an investigation. End-to-end audit trails in insurance fraud investigation software maintain records of decisions, communications, and system actions—critical for defending against legal challenges and passing regulatory reviews.
Top-tier insurance fraud software also supports multilingual, multi-jurisdictional environments—critical for global carriers operating under diverse legal and operational requirements.
Core Technologies Behind Fraud Detection Platforms
A suite of technologies powers leading insurance fraud investigation software:
- Logistic Regression: Best for initial benchmarks but limited in skewed datasets.
- Modified Multivariate Gaussian (MVG): Effective for distance-based anomaly scoring.
- Boosting Algorithms: Ensemble learning that improves predictive accuracy.
- Bagging with Adjusted Random Forest: Delivers high recall and precision even with unbalanced data.
- Principal Component Analysis (PCA): Reduces dimensionality for faster and more reliable predictions.
These models are layered in a modular architecture, enabling tailored fraud strategies for different lines of business.
Compliance and Data Privacy Considerations
Insurance companies operate in a highly regulated environment where compliance is not optional; it is a legal and ethical imperative. The deployment of insurance fraud detection software must meet not only technical performance benchmarks but also legal standards for data governance, transparency, and customer rights.
- GDPR, HIPAA, CCPA: Different regions impose unique mandates around personal data handling, consent, and rights to data erasure. Systems must incorporate tools to handle requests, store only essential data, and audit access in accordance with these laws.
- Model Explainability: Insurers must provide clear, legally defensible explanations for any adverse decisions based on predictive models. This requires interpretable AI models or frameworks that enable real-time visibility into how decisions are made.
- Audit Readiness: Software must log and archive every system action, analyst decision, and data transformation. These detailed audit trails are essential for regulatory inspections, legal defenses, and internal compliance reviews.
- Security: Data security underpins privacy. Top-grade insurance fraud software must use advanced encryption standards, multifactor authentication, intrusion detection systems, and secure APIs to ensure data integrity and protection from breaches.
Beyond these, insurers are increasingly expected to build trust through transparency and accountability. Regulatory frameworks continue to evolve, and staying compliant requires technology that’s adaptable, auditable, and built with privacy in mind.
Real-World Use Cases and Insights
In the field, insurance fraud detection software has demonstrated tangible success. Analyzing claim data with AI-driven tools uncovers hidden trends and behaviors that traditional systems miss. These insights not only improve detection but also guide risk management strategies.
- Holiday Claims: Claims filed around public holidays showed a significantly higher fraud rate. Roughly 11% of fraudulent claims occurred during holiday weeks, and such claims are 80% more likely to be flagged due to the suspicious timing and event patterns.
- Vehicle Age Patterns: Vehicles aged 6–8 years were involved in 82% of detected fraud cases, suggesting fraudsters target older cars for staged accidents or inflated damage reports. This insight helps prioritize fraud risk scoring.
- Witness and Police Report Gaps: 99.6% of fraudulent claims lacked a listed witness and only 2% were reported to police. These red flags are strong indicators in fraud models, especially when legitimate claims consistently involve official reports.
- License Data Anomalies: In 75% of fraud cases, license data was either missing or marked as unknown. Such anomalies are weighted heavily in the fraud risk models and can trigger further scrutiny.
By deploying Adjusted Random Forest and ensemble modeling, insurers saw detection precision improve by over 1600 times when compared to traditional rule-based benchmarks. These insights prove that advanced models don’t just automate detection; they dramatically elevate results.
Feature Engineering and Model Optimization
Advanced insurance fraud detection software development relies on robust feature engineering to uncover relationships that might otherwise be missed. This process transforms raw data into structured variables that machine learning models can interpret with high predictive value.
- Domain-Based Features: Combining industry knowledge with data science, analysts derive features like party involvement frequency, claim clustering, vehicle history, and risk indicators such as holiday timing or third-party interactions.
- Geospatial Clustering: By grouping claims data by zip code, city, or incident hotspots, systems can identify fraud rings or staged accident patterns specific to certain regions. This geolocation intelligence improves targeting and model localization.
- Temporal Features: Claims submitted unusually quickly or suspiciously delayed are often indicative of fraud. Models use time lags between incident date and filing date, policy start date and claim date, or renewal vs. lapse data to add fraud probability context.
- Dimensionality Reduction: Too many irrelevant features can dilute model performance. Using techniques like PCA (Principal Component Analysis), developers reduce data noise, isolate dominant variables, and create more efficient, faster, and scalable models.
The inclusion of techniques like forward selection, backward elimination, and wrapper methods ensures the best-performing features are used, boosting both accuracy and computational efficiency.
Performance Metrics That Matter
Executives need quantifiable evidence that fraud detection tools deliver business value. Effective insurance fraud investigation software is measured not just by detection rate, but by how well it balances accuracy, resource allocation, and user trust.
- Recall: Measures the percentage of actual fraud cases correctly identified. High recall is essential when missing fraud can result in significant financial losses.
- Precision: Indicates how many flagged cases are genuinely fraudulent. A model with high precision saves investigative resources by minimizing false positives.
- F1 and F5 Scores: These combine precision and recall into a single metric. F1 balances both equally, while F5 emphasizes recall; useful in scenarios where missing fraud is more costly than investigating false alerts.
- AUC (Area Under Curve): Assesses how well the model distinguishes between fraud and non-fraud across all classification thresholds. Higher AUC means better overall discrimination.
Additionally, cost functions are employed to dynamically adjust model behavior. Depending on business goals; whether to reduce losses or operational costs, models can be tuned to either prioritize fraud coverage or investigation efficiency.
How Neuronimbus Can Help with Insurance Fraud Detection Software Development
Neuronimbus delivers end-to-end expertise in insurance fraud detection software development for insurers seeking custom, high-performance solutions. Our comprehensive approach blends AI, big data, and regulatory expertise.
- Custom Model Development: We design models tailored to your claims patterns and fraud risks, including ensemble methods like Boosting and Random Forest.
- Big Data Integration: We unify structured policy and claims data with unstructured sources such as call logs, adjuster notes, and third-party databases.
- Cloud-Native Platforms: Our scalable architecture enables real-time data processing, flexible deployment, and rapid model iteration.
- Compliance by Design: We ensure every solution aligns with GDPR, HIPAA, and local data protection standards, incorporating encryption, audit logging, and model transparency.
Neuronimbus enables insurers to detect and prevent fraud with greater speed, accuracy, and accountability; resulting in minimized losses, faster claims handling, and an enhanced customer experience.



